How to Scrape ZipRecruiter Job Listings (Step-by-Step Guide)
If you want to scrape ZipRecruiter job listings for recruitment intelligence, sales prospecting, or US labor market research, this guide walks you through the entire process. You will learn what data you can extract, how to automate the collection, and how to turn ZipRecruiter postings into actionable hiring intelligence.
Why Scrape ZipRecruiter Job Data?
ZipRecruiter is one of the largest job marketplaces in the United States, connecting millions of job seekers with employers across every industry. It aggregates job postings from company career pages, recruiter networks, and direct employer postings — making it one of the most comprehensive single sources of US job listing data available.
Businesses and researchers scrape ZipRecruiter job data for several reasons:
- US hiring signals — companies posting on ZipRecruiter are actively investing in headcount, which is a reliable indicator of growth and budget
- Salary benchmarking — analyze compensation ranges across roles, locations, and employment types in the US market
- Sales prospecting — identify companies hiring for roles that indicate demand for your product or service
- Recruitment analytics — track which skills, titles, and companies are posting the most in your target market
- Job market research — study hiring volumes, salary trends, remote work adoption, and demand shifts across US industries
- Lead enrichment — add US hiring signals to your CRM to prioritize outreach to fast-growing companies
Manually browsing ZipRecruiter and copying job details is impractical at any meaningful scale. A keyword search can return thousands of listings across dozens of pages, and new postings appear continuously. Automation is the only realistic approach for collecting ZipRecruiter data at scale.
What Data You Can Extract from ZipRecruiter
The ZipRecruiter Jobs Scraper extracts structured data from job search results. Here are the key fields you can collect:
| Field | Description | Example |
|---|---|---|
| Job title | The title of the position | Senior Software Engineer |
| Company name | The hiring organization | TechCorp Inc. |
| Location | City, state, or remote designation | San Francisco, CA |
| Salary | Compensation range as listed | $150,000 - $200,000 a year |
| Job description | Full text of the job posting | We are looking for a Senior Software Engineer... |
| Employment type | Contract type | Full-Time, Part-Time, Contract |
| Job URL | Direct link to the ZipRecruiter listing | ziprecruiter.com/jobs/... |
| Posted date | When the listing was published | 2025-01-15T12:34:56.789Z |
| Search query | The keyword used in the search | software engineer |
| Search location | The location used in the search | San Francisco, CA |
| Scraped at | Timestamp when the listing was collected | 2025-01-15T12:34:56.789Z |
This is the kind of structured data that would take hours to compile manually. With a scraper, you can extract hundreds of ZipRecruiter job listings across multiple roles and locations in minutes.
Common Use Cases for ZipRecruiter Job Data
US Hiring Intelligence for B2B Sales
ZipRecruiter job data is a powerful signal for B2B sales teams targeting the US market. A company actively posting roles on ZipRecruiter is investing in growth — which means they likely have budget and are evaluating new tools, services, and vendors.
Use ZipRecruiter data to build prospect lists of companies currently expanding. A company posting for "DevOps Engineers" is probably evaluating cloud infrastructure tools. A company hiring "Sales Development Representatives" is scaling their go-to-market motion. The job title tells you what they are about to buy.
Salary Benchmarking
ZipRecruiter includes salary ranges on a significant portion of listings, making it one of the better sources for US compensation data. Use this data to benchmark salaries for specific roles across cities, states, and employment types. Understand how compensation for a given title varies between San Francisco, Austin, and New York — or between full-time and contract arrangements.
This is valuable for HR teams setting competitive compensation, recruiters advising candidates, and analysts studying US labor market dynamics.
Recruitment Analytics
Recruiting firms and in-house talent acquisition teams use ZipRecruiter data to stay ahead of the market. Track which roles are in highest demand, how quickly postings are being filled, and what qualifications employers are consistently requiring.
Monitor how demand for specific job titles — software engineer, data scientist, product manager — shifts across quarters. This intelligence helps recruiters position candidates more effectively and advise clients on realistic hiring timelines and competitive packages.
Job Market Research
Researchers and analysts use ZipRecruiter data to study the US labor market in depth. Analyze hiring volumes by industry, company size, and geography. Track remote work adoption by comparing remote-designated listings against location-specific ones. Study how employment types (full-time vs contract vs part-time) vary across sectors.
ZipRecruiter's scale across all major US industries makes it a uniquely comprehensive data source for broad labor market analysis.
Competitive Intelligence
Track what your competitors are hiring for. Companies posting roles publicly on ZipRecruiter are broadcasting their strategic priorities. A competitor hiring a "Head of Partnerships" signals a new channel strategy. A company posting five "Machine Learning Engineer" roles signals a major AI investment.
Monitoring competitor hiring patterns on ZipRecruiter provides an early indicator of their product roadmap and go-to-market strategy.
Lead Enrichment
Add US hiring signals to your existing CRM or prospect data. When you know a target company is actively hiring in a specific function, your outreach becomes far more relevant and timely. Combine ZipRecruiter data with company firmographic data to build comprehensive, signal-enriched prospect profiles.
Challenges of Extracting ZipRecruiter Data Manually
Before jumping into the tutorial, it is worth understanding why ZipRecruiter requires automation:
- Volume — ZipRecruiter surfaces hundreds to thousands of results for any keyword-location combination. Manually reviewing even 50 listings is tedious; collecting 500 is infeasible
- Pagination — results are spread across multiple pages. Tracking page state and collecting consistently across pages requires systematic handling
- Salary parsing — ZipRecruiter displays salary ranges in varying formats (hourly, annual, estimated). Normalizing these for analysis requires careful parsing
- Full descriptions — extracting the complete job description text at scale, not just listing summaries, requires following individual listing URLs
- Anti-bot measures — ZipRecruiter uses browser fingerprinting and bot detection. Reliable extraction requires proper browser emulation and proxy management
- Freshness — new postings appear and old ones expire constantly. Any manual snapshot is stale within hours for active search categories
Building and maintaining a ZipRecruiter scraper that handles all of this correctly is a significant engineering investment.
Step-by-Step: How to Scrape ZipRecruiter Job Listings
Here is how to scrape ZipRecruiter job data using the ZipRecruiter Jobs Scraper on Apify.
Step 1 — Define Your Search
Start by deciding what roles and locations you want to target. The ZipRecruiter Jobs Scraper is search-based, mirroring how you would search on ZipRecruiter directly:
- Keyword — the job title or skill you want to search for (e.g.
software engineer,data analyst,product manager,nurse) - Location — a city and state (e.g.
San Francisco, CA), a state name, orRemotefor location-agnostic postings
You can be as specific or broad as you need. Searching "python developer" + "Austin, TX" targets a tight segment; searching "engineer" + "United States" casts a wide net.
Step 2 — Configure the Scraper Input
Head to the ZipRecruiter Jobs Scraper on Apify and configure your run:
- Enter your search keyword — the job title or role to search for
- Enter the location — city/state, state, or "Remote"
- Set maxPages — how many pages of results to scrape (1–20, default 3)
- Optionally adjust maxRequestsPerCrawl as a safety cap on total page loads
- Click Start to begin the extraction
The scraper handles pagination automatically, collecting all results up to your specified page limit.
Step 3 — Run the Scraper
Once started, the scraper will:
- Launch a headless browser with residential proxies to reliably access ZipRecruiter
- Query ZipRecruiter with your keyword and location
- Crawl through all result pages up to your
maxPageslimit - Extract structured listing data from each result
- Store results in a clean, structured dataset
The scraper uses Playwright with residential proxies to ensure consistent, reliable extraction.
Step 4 — Export Structured Results
Once the scraper finishes, export your results in your preferred format:
- JSON — ideal for developers building data pipelines or integrations
- CSV — perfect for analysis in Excel or Google Sheets, or importing into a CRM
- API — access results programmatically via the Apify API for automated workflows
Each record includes the full set of structured fields: job title, company, location, salary, description, employment type, and direct job URL.
Ready to try it? Run the ZipRecruiter Jobs Scraper on Apify and get your first dataset in minutes.
Example Output (Real Data Preview)
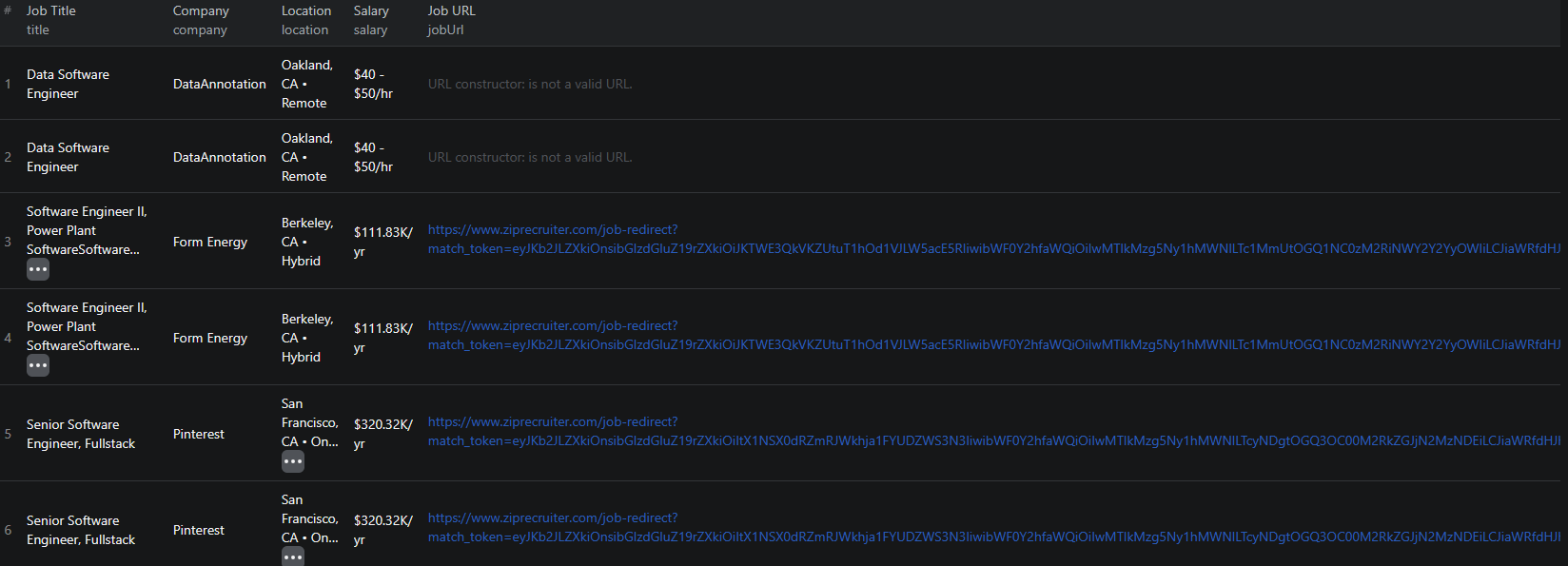
Here is what the actual output looks like from the ZipRecruiter Jobs Scraper. Each job listing returns a structured JSON object:
{
"title": "Senior Software Engineer",
"company": "TechCorp Inc.",
"location": "San Francisco, CA",
"salary": "$150,000 - $200,000 a year",
"jobUrl": "https://www.ziprecruiter.com/jobs/...",
"description": "We are looking for a Senior Software Engineer to join our team...",
"postedDate": null,
"employmentType": "Full-Time",
"scrapedAt": "2025-01-15T12:34:56.789Z",
"searchQuery": "software engineer",
"searchLocation": "San Francisco, CA"
}
Key things to notice:
- Salary range — compensation as listed by the employer, useful for benchmarking without any normalization required from the raw text
- Full description — the complete job posting text, enabling keyword analysis, skill extraction, and requirement parsing at scale
- Employment type — full-time, part-time, or contract designation for filtering by work arrangement
- Search context —
searchQueryandsearchLocationare included in every record, making it easy to segment results when running multiple searches in batch - Direct job URL — a link to the full ZipRecruiter listing for quick reference or further research
- Scraped timestamp —
scrapedAtrecords exactly when the data was collected, essential for time-series analysis
This structured format is ready to import into any CRM, database, or analytics tool without additional processing.
Try the ZipRecruiter Jobs Scraper now — no coding required.
Automating ZipRecruiter Data Collection
For ongoing recruitment monitoring or sales prospecting, you do not want to run the scraper manually every time. The Apify platform supports full automation:
Scheduled Runs
Set up recurring scrapes on any schedule — daily, weekly, or monthly. The scraper runs automatically and stores results in a persistent dataset you can access at any time. Daily runs are ideal for time-sensitive recruitment and sales use cases; weekly runs work well for broader market research.
API Integration
Use the Apify API to trigger scraper runs programmatically and retrieve results. This lets you integrate ZipRecruiter job data into your existing workflows:
- Feed new job listings into your CRM or ATS automatically
- Trigger alerts when target companies post new roles in your focus area
- Build dashboards that update with fresh US hiring data
- Connect to tools like Zapier, Make, or custom data pipelines
Hiring Signal Pipelines
Combine scheduled ZipRecruiter scraping with company-level aggregation to build hiring signal systems. Track which companies are posting the most roles over time, which are expanding into new locations, and which are hiring for roles that signal strategic shifts. These signals are powerful for both sales teams and investors watching US market dynamics.
Node.js Example
For a complete working example showing how to call this scraper from Node.js, see the GitHub repository.
Webhooks
Configure webhooks to get notified when a scraper run completes. This is useful for event-driven architectures where you want to process new job data as soon as it is available rather than polling on a schedule.
Using ZipRecruiter Data for Job Market Analysis
ZipRecruiter's breadth across US industries and geographies makes it an excellent source for labor market analysis.
Salary Trend Analysis
Track how salary ranges for specific roles evolve over time. Identify which cities pay the most for a given title, how compensation for contract versus full-time roles compares, and how salary expectations are shifting across industries. ZipRecruiter's salary data provides ground-truth compensation intelligence that supplements traditional survey-based benchmarks.
Skill and Title Demand Tracking
Analyze which job titles and implied skill sets are appearing most frequently in ZipRecruiter results. Track how demand for specific roles — data engineer, ML engineer, product designer — shifts across quarters. This intelligence helps training companies, bootcamps, and career advisors identify the most in-demand skills in the US market.
Geographic Hiring Patterns
Use location data to map where US companies are hiring. Track which cities and states are gaining the most hiring activity in your target industry, which metros are seeing declining postings, and how remote work is distributed across sectors. This geographic dimension adds important context for economic research and location strategy decisions.
Company-Level Hiring Intelligence
Aggregate ZipRecruiter data at the company level to build a picture of individual company hiring velocity and strategic direction. Companies posting large volumes of roles are scaling fast. Companies shifting hiring from one function to another are pivoting their strategy. This intelligence is valuable for investors, competitive analysts, and enterprise sales teams alike.
Does ZipRecruiter Offer an API?
ZipRecruiter does not provide a broadly available public API for extracting job listing data at scale:
Limited Partner Access
ZipRecruiter has a job distribution API for ATS and HR platform partners, but it is not accessible to most businesses or developers. Even where partner access exists, it is scoped to job posting rather than data extraction.
Manual Export Limitations
You can manually browse ZipRecruiter and copy job details, but this scales to only a handful of listings at a time. Beyond 20–30 jobs, manual collection becomes impractical and error-prone.
The Practical Alternative
For most teams that need structured ZipRecruiter data at scale, a web scraper is the practical solution. The ZipRecruiter Jobs Scraper extracts the same publicly visible job listings that anyone can see by visiting ZipRecruiter — without requiring API access or custom infrastructure.
Why Use a Pre-Built ZipRecruiter Scraper Instead of Building One
Building a custom ZipRecruiter scraper is harder than it looks:
- Anti-bot protection — ZipRecruiter uses browser fingerprinting and bot detection that blocks naive scrapers. Reliable extraction requires proper browser emulation via tools like Playwright and residential proxy rotation
- Pagination complexity — consistently crawling through multiple result pages without triggering rate limits requires careful request management
- Salary format variability — ZipRecruiter displays salaries in multiple formats (hourly, annual, estimated ranges). Parsing these reliably requires format-aware extraction logic
- Maintenance overhead — ZipRecruiter updates its frontend regularly. Every update can break a custom scraper, requiring immediate fixes to keep your data pipeline running
- Infrastructure costs — residential proxies, browser automation, and distributed crawling add up. Building this stack from scratch carries significant setup and ongoing operational cost
- Opportunity cost — every hour spent building scraper infrastructure is an hour not spent analyzing data or closing deals
Using a maintained, pre-built solution means you focus on what to do with ZipRecruiter data instead of how to collect it.
Try the ZipRecruiter Jobs Scraper
The ZipRecruiter Jobs Scraper extracts structured data from ZipRecruiter job listings — titles, companies, locations, salaries, descriptions, employment types, and direct apply links.
What you get:
- Structured JSON or CSV output ready for analysis
- All key job and company data fields in a single export
- Keyword and location search targeting any US market segment
- Up to 20 pages of results per search run
- Scheduled runs for ongoing hiring signal monitoring
- API access for integration into your workflows
- No coding or scraper maintenance required
Start scraping ZipRecruiter now — your first run takes less than 5 minutes to set up.
If you are building a US hiring intelligence pipeline, combine ZipRecruiter data with Dice job listings for deeper tech market coverage, or LinkedIn decision-maker data to enrich your prospect profiles with contact information.
Legal and Ethical Considerations
Web scraping occupies a well-established legal space, but responsible practice matters:
- Public data only — the ZipRecruiter Jobs Scraper extracts publicly visible job listings that anyone can see by visiting ZipRecruiter. No login or authentication is required
- Privacy compliance — job listings contain company and role data, not personal information about candidates. Handle any data you collect in compliance with applicable regulations
- Respect rate limits — the scraper is designed to make requests at a reasonable pace to avoid overloading ZipRecruiter's servers
- Responsible use — use the data for legitimate business purposes such as recruitment, sales intelligence, and market research
Frequently Asked Questions
Is scraping ZipRecruiter legal?
Scraping publicly available job listings from ZipRecruiter is generally legal. The postings are visible to anyone who visits the site without logging in. However, you should always use the data responsibly, comply with applicable privacy regulations, and avoid overloading ZipRecruiter's servers with excessive requests.
Does ZipRecruiter offer an API?
ZipRecruiter offers a limited partner API for job distribution, but it is not broadly available for data extraction purposes. Most businesses and developers cannot access comprehensive job listing data programmatically through official channels. A scraper is the practical alternative for extracting structured ZipRecruiter data at scale.
What data can be extracted from ZipRecruiter job listings?
You can extract job titles, company names, locations, salary ranges, full job descriptions, employment types, direct apply links, search query context, and scrape timestamps. Each listing is returned as a structured JSON object.
Can I search ZipRecruiter by location and keyword?
Yes. The ZipRecruiter Jobs Scraper accepts both a search keyword (e.g. software engineer, data analyst) and a location (e.g. San Francisco, CA, Remote). You can target any combination of role and geography to extract exactly the job listings you need.
How many ZipRecruiter listings can I scrape?
The scraper supports up to 20 pages of search results per run. Each page typically contains multiple listings, giving you broad coverage of any keyword-location combination on ZipRecruiter.
Can I export ZipRecruiter job listings to CSV?
Yes. The ZipRecruiter Jobs Scraper supports exporting results as JSON, CSV, or via API. CSV exports can be opened directly in Excel or Google Sheets for analysis and CRM import.
About the Author
This guide was written by Piotr, a software engineer with hands-on experience building and maintaining web scrapers at scale. He develops and maintains a suite of data extraction tools on the Apify platform, helping businesses automate their data collection workflows.
Need help with your scraping project?
Book a free discovery call and let's scope your project together.
Book a Call