How to Scrape Temu Product Listings (Step-by-Step Guide)
If you want to scrape Temu product listings for price monitoring, market research, or competitor analysis, this guide walks you through the entire process. You will learn what data you can extract from Temu product pages, how to handle Temu's anti-bot protections and localized currencies, and how to turn raw listings into actionable cross-border e-commerce intelligence.
Why Scrape Temu Data?
Temu is a cross-border e-commerce marketplace owned by PDD Holdings — the same parent company behind Pinduoduo, China's third-largest e-commerce player. Launched in 2022, Temu has grown faster than almost any consumer app in history, becoming one of the most-downloaded shopping apps in the United States, the European Union, the United Kingdom, Australia, Japan, Korea, Latin America, and dozens of other markets within its first 24 months. Its model is straightforward: connect Western and global shoppers directly to factory-direct suppliers in China at prices most domestic marketplaces cannot match.
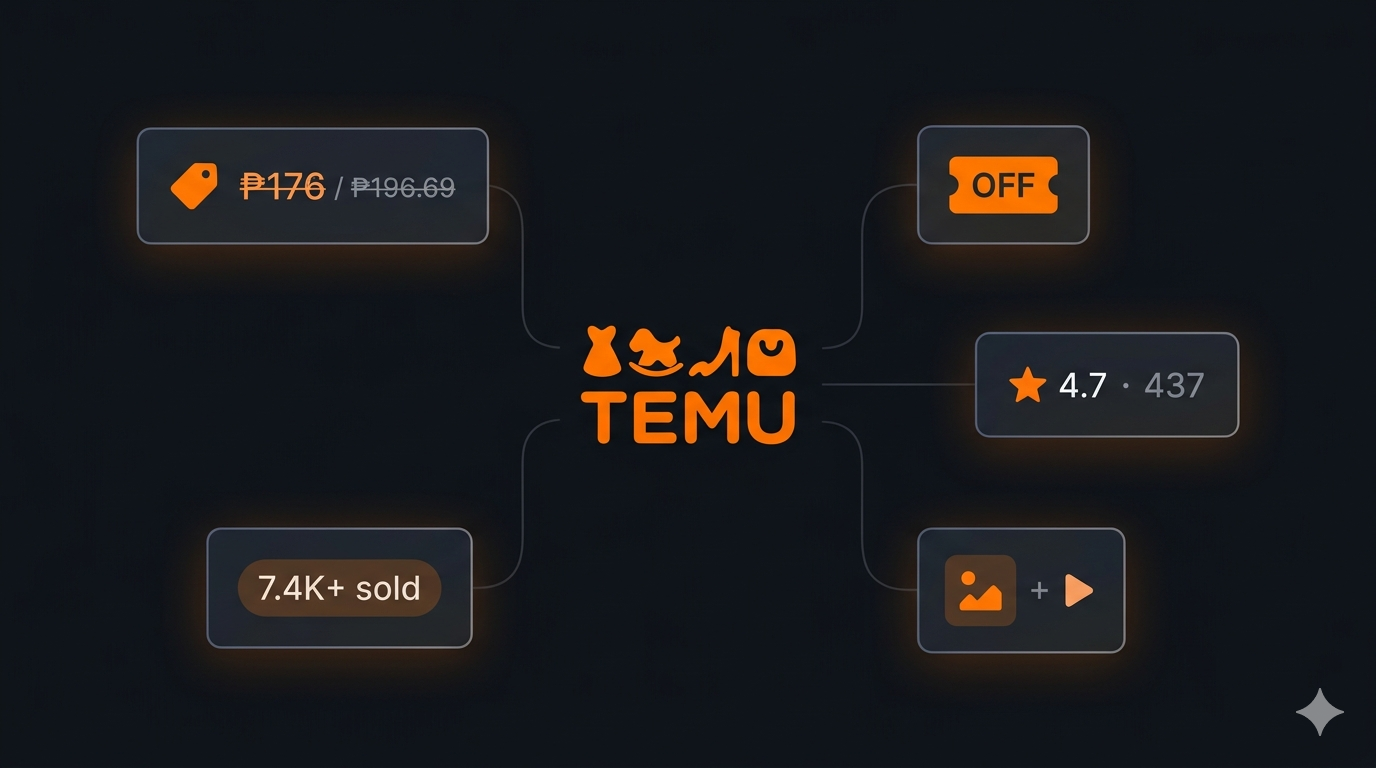
What makes Temu valuable as a data source is the breadth of structured information surfaced on every product page: current price and original price in local currency, a clean discount percentage, sales count, star rating, review count, the full image gallery, video URLs, and the underlying store ID. Combined, these fields tell you not just what a product costs — but how aggressively it is priced, how much it has sold, and which factory storefront is behind it.
Businesses and researchers scrape Temu data for a range of purposes:
- Cross-border price intelligence — track local-currency prices and discount percentages on Temu's ultra-low-cost SKUs in real time
- Pricing pressure analysis — quantify how much cheaper Temu listings are than equivalent SKUs on Amazon, eBay, or local marketplaces
- Catalog & assortment research — map the full Temu assortment by category, brand, and price band
- Store / supplier mapping — group products by
storeIdto identify which Chinese factory storefronts are driving a category - Demand proxy via sales counts — Temu surfaces sold counts (e.g.
7.4K+) on every product, a strong leading indicator of demand - Cross-marketplace comparison — pair Temu data with 1688.com, AliExpress, DHgate, or TikTok Shop to build a full picture of the China-to-world e-commerce stack
Manually browsing Temu and copy-pasting product details is impractical at any meaningful scale — Temu serves dozens of localized storefronts, ranks results per visitor, and rotates promotional pricing constantly. Automation is the only realistic approach.
What Data You Can Extract from Temu
The Temu Listings Scraper extracts structured product data from any Temu product detail page URL. Here are the key fields available:
| Field | Description | Example |
|---|---|---|
| ID | Temu's unique product (goods) identifier | 601099769178067 |
| Title | Full product title as displayed on the PDP | 2pcs Men's Suit Fashion Set Jacket Suit and Trousers |
| Description | Normalized product description | 2pcs mens suit fashion set jacket suit and trousers |
| Price | Current selling price in the storefront's local currency | 176 |
| Original price | List price before discount | 196.69 |
| Discount percentage | Discount off original price (%) | 1 |
| Currency | ISO currency code of the storefront | PLN |
| Sales count | Sold-count badge (kept as string to preserve K+ formatting) | 7.4K+ |
| Rating | Average star rating (0–5) | 4.7 |
| Total reviews | Total number of reviews | 437 |
| Image URL | Primary product image (CDN URL) | img.kwcdn.com/product/...jpg |
| Additional images | Array of secondary CDN image URLs | ["img.kwcdn.com/...", "..."] |
| Video URL | Product video URL when present | goods-vod.kwcdn.com/...mp4 |
| Store ID | Identifier of the supplier storefront behind the listing | 634418212822033 |
| Product URL | Canonical URL of the source PDP | temu.com/goods.html?goods_id=... |
Every record is keyed by id (the Temu goods ID) and carries the full original productUrl, so the dataset deduplicates and audits cleanly across runs.
Common Use Cases for Temu Data
Cross-Border Price Monitoring
Temu exposes both the current selling price and the original price plus a clean discount percentage on every listing. Scraping these fields on a schedule lets you build a real-time view of how aggressively Temu is undercutting domestic marketplaces in each region, and how prices move during peak shopping events.
Pricing Pressure Analysis
For brands and retailers, the most important question about Temu is rarely "what does Temu cost?" — it is "how much cheaper is Temu than my channel?" Scrape an equivalent basket of SKUs on Temu and compare against your own pricing (or Amazon, eBay, or local marketplaces) to quantify the price-pressure gap product by product.
Supplier & Store Mapping
The storeId field identifies the supplier storefront behind every listing. Grouping products by storeId lets you see which Chinese factory storefronts are driving share in a category, and how diversified Temu's catalog is by supplier vs. concentrated in a handful of dominant stores.
Demand Proxy via Sales Counts
Temu surfaces a sold-count badge (e.g. 7.4K+) on every product. While the value is bucketed, aggregating sold counts by brand, price band, or category provides a much stronger demand signal than rating alone — particularly useful for ranking sourcing opportunities or identifying breakout SKUs.
Catalog & Assortment Mapping
Run the scraper across a curated seed list of Temu product URLs for a category and you have a clean snapshot of the assortment — every title, price, rating, review count, and image. From there it is straightforward to roll up by price band, brand, or store and identify gaps in your own catalog relative to what's selling on Temu.
Image & Video Asset Collection
Each record includes the primary image URL, an additionalImages array, and a videoUrl when present. This is useful for visual research workflows — for example, classifying products by visual style with an embedding model, or studying which product videos correlate with high sold counts.
Cross-Marketplace Comparison
Pair Temu data with 1688.com for upstream factory-direct sourcing, AliExpress for cross-border China-to-world pricing, DHgate for wholesale, or TikTok Shop for live-commerce. Together they give you a full picture of how Chinese supply chains reach global consumers.
Challenges of Scraping Temu Manually
Before jumping into the tutorial, it is worth understanding why building your own Temu scraper is harder than it looks:
- PDD-grade anti-bot stack — Temu inherits PDD Holdings' anti-bot platform, which combines TLS fingerprinting, encrypted request signing, and behavioral analysis. Plain HTTP clients get blocked almost immediately, and even headless-browser setups get challenged routinely
- Heavy URL parameterization — Temu product URLs carry encrypted parameters like
_oak_mp_inf,top_gallery_url, andspec_gallery_idthat influence what the server returns. Stripping them naïvely can produce different results - Per-region storefronts and currencies — Temu serves localized content per region with different currencies, languages, and promotional pricing. A request from the wrong region routinely returns different prices and even different SKUs
- Personalized rankings — Temu's search and homepage feeds are aggressively personalized, so search-page scraping is unreliable for repeatable research. Product detail pages are the stable surface
- Frontend churn — Temu updates its layout, API surface, and signing logic regularly, breaking custom scrapers that are not actively maintained
- Image and video CDNs — Temu uses Kwai's
kwcdn.cominfrastructure for both images and product videos, which requires careful URL handling for downstream pipelines
For most use cases, a pre-built and maintained scraper is dramatically more practical than building one in-house.
Step-by-Step: How to Scrape Temu Product Listings
Here is how to scrape Temu product data using the Temu Listings Scraper on Apify.
Step 1 — Gather Your Target Product URLs
The scraper is URL-driven, so the first step is to assemble a list of Temu product detail page URLs you want structured data for. A valid Temu product URL looks like this:
https://www.temu.com/goods.html?goods_id=601099769178067&...
You can pull URLs from:
- Browsing Temu in your target region and copying the canonical product URL
- Affiliate feeds or category seed lists
- Your existing competitive-intelligence trackers
- A previous Temu run's output (the scraper returns the canonical
productUrlon every record)
The extra query parameters on Temu URLs are fine — the scraper handles them automatically.
Step 2 — Configure the Scraper Input
Head to the Temu Listings Scraper on Apify and configure your run by providing your array of product URLs.
Example input:
{
"startUrls": [
"https://www.temu.com/goods.html?goods_id=601099769178067",
"https://www.temu.com/goods.html?goods_id=601099952001588"
]
}
Step 3 — Run the Scraper
Once started, the scraper will:
- Iterate through every URL in
startUrls - Survive Temu's anti-bot protections via managed residential proxies in the target region
- Extract structured title, price, original price, discount percentage, currency, sales count, rating, review count, and store ID from each PDP
- Pull the full image gallery (primary image plus
additionalImages) and the product video URL when present - Stream results to the dataset as they are scraped
Most runs of a few hundred product URLs complete in a couple of minutes.
Step 4 — Export Your Results
When the scraper finishes, export your data in the format you need:
- JSON / JSONL — ideal for developers building integrations or price-monitoring pipelines
- CSV — perfect for spreadsheet analysis or importing into BI tools
- Excel / HTML / XML — for sharing with non-technical stakeholders
- API — access results programmatically via the Apify API for automated workflows
Ready to try it? Run the Temu Listings Scraper on Apify and get your first dataset in minutes.
Example Output (Real Data Preview)

Here is what the actual output looks like. Each product is returned as a structured JSON object:
{
"id": "601099769178067",
"title": "2pcs Men's Suit Fashion Set Jacket Suit and Trousers Elegant Business Casual Banquet Party",
"description": "2pcs mens suit fashion set jacket suit and trousers elegant business casual banquet party",
"price": 176,
"originalPrice": 196.69,
"discountPercentage": 1,
"currency": "PLN",
"salesCount": "7.4K+",
"rating": 4.7,
"totalReviews": "437",
"imageUrl": "https://img.kwcdn.com/product/fancy/4b9f58cb-9d38-4d66-9a6e-d4be3e179647.jpg",
"additionalImages": [
"https://img.kwcdn.com/product/fancy/4b9f58cb-9d38-4d66-9a6e-d4be3e179647.jpg",
"https://img.kwcdn.com/product/fancy/da7dd1b0-2479-4cb4-b808-ea9027e279b0.jpg",
"https://img.kwcdn.com/product/fancy/3f690c9d-a63e-4a84-a7a3-936a27a26173.jpg"
],
"videoUrl": "https://goods-vod.kwcdn.com/goods-video/b99e09f76414cc6c3aafc51a034430731169f12d.f30.mp4",
"storeId": 634418212822033,
"productUrl": "https://www.temu.com/goods.html?_bg_fs=1&goods_id=601099769178067&..."
}
And a second record without a product video:
{
"id": "601099952001588",
"title": "[Lightweight Design] Men's 3pcs Formal Suit Set - Solid Color, Includes Lapel Blazer, Vest, and Dress Pants - Ideal for Business Events, Graduations, Weddings, and Parties",
"description": "lightweight design mens 3pcs formal suit set solid color lapel vest and dress pants ideal for business events graduations weddings and parties",
"price": 241.9,
"originalPrice": 304.63,
"discountPercentage": null,
"currency": "PLN",
"salesCount": "1.2K+",
"rating": 4.7,
"totalReviews": "52",
"imageUrl": "https://img.kwcdn.com/product/fancy/9873815e-3e00-4845-a34e-adbe89bccf0c.jpg",
"additionalImages": [
"https://img.kwcdn.com/product/fancy/9873815e-3e00-4845-a34e-adbe89bccf0c.jpg",
"https://img.kwcdn.com/product/fancy/33277889-a371-4682-af19-0d89cdb671c1.jpg"
],
"videoUrl": null,
"storeId": 634418218128554,
"productUrl": "https://www.temu.com/goods.html?_bg_fs=1&goods_id=601099952001588&..."
}
Key things to notice:
- Price and original price side by side — the headline
priceis the current selling price, whileoriginalPricepreserves the pre-discount list price for clean discount math - Currency on every record — no implicit assumptions; USD, EUR, GBP, PLN, JPY, and other currencies are surfaced as ISO codes per the source storefront
- Sales count as a formatted string — Temu surfaces sold counts as bucketed badges like
7.4K+or1.2K+, so the field is kept as a string to preserve the original signal without lossy parsing - Numeric
ratingand stringtotalReviews— ratings are float-typed for direct numeric use; review counts are strings to handle Temu's bucketed display formats videoUrlisnullwhen absent — easy to filter records that have video assets vs. those that don't- Full image gallery in
additionalImages— every PDP's gallery is preserved so you can build downstream image pipelines (visual search, catalog enrichment, ad-creative generation) storeIdfor supplier grouping — every record carries the underlying supplier identifier so you can roll up by store and study supply-side concentration
Try the Temu Listings Scraper now — no coding required.
Automating Temu Data Collection
For ongoing Temu intelligence, you do not want to run the scraper manually every time you need fresh data. The Apify platform supports full automation:
Scheduled Runs
Set up recurring scrapes on any schedule — hourly, daily, or weekly. The scraper runs automatically and stores results in a dataset you can access anytime. Daily runs are typically enough for catalog tracking; hourly runs work well for price-pressure monitoring against your own SKUs during peak promotional windows.
API Integration
Use the Apify API to trigger scraper runs programmatically and retrieve results. This lets you integrate Temu data into your existing analytics workflows:
- Feed new listings into your price-monitoring pipeline
- Trigger alerts when a tracked SKU drops below a target price
- Sync Temu catalog data into your BI warehouse
- Connect to tools like Zapier, Make, or custom data pipelines
Node.js Example
For a complete working example showing how to call this scraper from Node.js, see the GitHub repository.
Webhooks
Configure webhooks to get notified when a scraper run completes. This is useful for event-driven architectures where you want to process new product data as soon as it is available — for example, kicking off a normalization or alerting job the moment a fresh Temu run finishes.
Using Temu Data for Market Intelligence
The structured data from Temu unlocks a range of analytical use cases.
Price-Pressure Index
Maintain a fixed basket of SKUs you sell (or compete with) and scrape the equivalent Temu listings on a schedule. Compute the per-SKU price gap (yourPrice - temuPrice) and aggregate to a category-level "Temu pressure" index. The result is a quantitative view of where Chinese cross-border supply is most threatening to your channel.
Discount Cadence Tracking
Temu runs near-continuous promotions. By scraping discountPercentage daily across a fixed basket of SKUs, you can quantify how often each product hits its peak discount, how long that discount lasts, and which sub-categories run the most aggressive promotional cadence.
Sold-Count Bucket Analysis
Aggregating bucketed sold counts (100+, 1K+, 10K+, etc.) by brand, store, or price band surfaces which products and price points are actually moving — a much stronger signal than rating alone, particularly for low-priced impulse categories where rating distributions are compressed near the top of the scale.
Store Concentration Analysis
Group records by storeId to see how concentrated Temu's catalog is per category. If 80% of a category's top SKUs come from a handful of stores, that has very different sourcing and competitive implications than a long-tail distribution across hundreds of suppliers.
Visual Catalog Enrichment
The imageUrl, additionalImages, and videoUrl fields enable downstream visual workflows — embedding-based similarity search, automatic style classification, or pulling ad-quality product imagery for internal catalog enrichment.
Does Temu Provide an API?
Temu does not offer a public catalog API. The closest official channel is the Temu Affiliate Program, which has serious limitations for data collection:
What's Available
- The affiliate program is restricted to approved partners promoting Temu links
- It is designed for tracking referral clicks and commission, not for browsing the full catalog
- Cross-seller search results, category browsing, and competitor SKUs are not exposed
- The structured price, discount, sales-count, and store data central to competitive analysis are not available via the program
What the API Misses
The official channel omits exactly the fields that make Temu data useful for market research: voucher-applied pricing, sold counts, supplier storeId, full image and video galleries, and the cross-currency normalization that public-page scraping makes trivial. For real cross-border e-commerce intelligence, a public-page scraper is the practical alternative.
The Temu Listings Scraper gives you structured product data from any Temu product URL — without affiliate approval or rate-limit gating.
Why Use a Temu Scraper Instead of Building One
Building a custom Temu scraper sounds straightforward until you actually start:
- PDD-grade anti-bot stack — Temu's anti-bot platform blocks plain HTTP requests within a few calls and routinely defeats headless browsers without serious investment in stealth tooling
- Encrypted URL parameters — Temu product URLs carry encrypted signing parameters that influence what the server returns. Stripping them naïvely produces different results
- Per-region storefronts — every parser, every URL builder, and every test has to account for multiple regional storefronts with different currencies and pricing
- Sold-count and review-count formatting — Temu surfaces these as bucketed badges (
7.4K+,1.2K+) which take care to handle without lossy parsing - Image and video CDN handling — Temu uses Kwai's
kwcdn.cominfrastructure for media, which needs careful URL handling for downstream pipelines - Frontend churn — Temu updates its layout and API surface frequently, and every update breaks unmaintained scrapers
- Opportunity cost — every hour spent fixing your scraper is an hour not spent on the analysis the scraper exists to support
Unless you have very specific requirements that no existing tool can meet, a maintained scraper lets you focus on insights instead of plumbing.
Try the Temu Listings Scraper
The Temu Listings Scraper extracts structured data from Temu product detail pages — IDs, titles, descriptions, current prices, original prices, discount percentages, currencies, sales counts, ratings, review counts, full image galleries, product videos, and supplier store IDs.
What you get:
- Structured JSON, JSONL, CSV, Excel, HTML, or XML output ready for any downstream tool
- URL-driven input — point it at any list of Temu product URLs and get clean structured records back
- Automatic anti-bot bypass via managed residential proxies
- Local-currency price preservation (USD, EUR, GBP, PLN, JPY, AUD, and more)
- Image gallery and product video URLs surfaced on every record
storeIdon every record for supplier-side analysis- Scheduled runs and API access for ongoing market intelligence
- No coding, no proxy management, no scraper maintenance
Start scraping Temu now — your first run takes less than 5 minutes to set up.
If you are building a cross-border data pipeline, combine Temu data with other China-to-world sources like 1688.com for upstream factory-direct sourcing, AliExpress for retail cross-border pricing, DHgate for wholesale, or TikTok Shop for live-commerce.
Legal and Ethical Considerations
Web scraping occupies a well-established legal space, but responsible practice matters:
- Public data only — the Temu scraper extracts publicly visible product information that anyone can see by visiting the site. No login or authentication is required
- Respect rate limits — the scraper is designed to make requests at a reasonable pace and handle Temu's anti-bot protections cleanly without aggressive hammering
- No misuse — use collected data for legitimate business purposes like price monitoring, catalog research, and competitive analysis. Do not use the data to create counterfeit listings or mislead buyers
- Compliance — different regions have different data-protection regimes (GDPR in the EU/UK, CCPA in California, etc.). The scraper extracts product and listing data, not personal data, but downstream use is your responsibility
Temu product listings are public marketplace data — they are designed to be found by buyers. Scraping this data for catalog research and price intelligence is aligned with the platform's intended purpose.
Frequently Asked Questions
What is Temu?
Temu is a cross-border e-commerce marketplace owned by PDD Holdings — the same parent company behind Chinese giant Pinduoduo. Launched in 2022, Temu connects shoppers across the US, Europe, the UK, Australia, Japan, Korea, and dozens of other markets directly to factory-direct suppliers in China at ultra-low prices. By total downloads it is one of the most-installed shopping apps in the world.
Is scraping Temu legal?
Scraping publicly available product data from Temu is generally legal. Product listings are visible to anyone who visits temu.com without logging in. You should always use the data responsibly, comply with local data-protection regulations in the country you operate in, and avoid overloading Temu's servers with excessive requests.
Does Temu provide a public API?
No. Temu does not offer a public catalog API. There is an affiliate program for approved partners, but it does not expose competitor catalog data, search results, or category browsing. A web scraper is the practical alternative for cross-seller catalog research and price monitoring.
Does the scraper handle Temu's regional pricing?
Yes. Temu serves localized pricing in dozens of currencies — USD, EUR, GBP, PLN, JPY, AUD, CAD, BRL, and more — depending on the storefront the product URL is from. The scraper preserves the original currency on every record so you can normalize downstream without ambiguity.
Why does Temu block most scrapers?
Temu inherits PDD Holdings' anti-bot stack, which combines TLS fingerprinting, encrypted request signing, and behavioral analysis. Most scrapers built with plain HTTP clients or headless browsers get blocked within a few requests. The Temu Listings Scraper survives these protections via managed residential proxies and proven request patterns — no Playwright or fragile stealth scripts required.
Can I scrape Temu search results or only product pages?
The current scraper is URL-driven and built around Temu product detail pages (temu.com/goods.html?goods_id=...). This is by design — product URLs are stable across sessions, where Temu search results are heavily personalized and re-ranked per visitor. For catalog discovery, gather product URLs from your own browsing, affiliate feeds, or category seed lists, then hand them to the scraper for structured extraction.
About the Author
This guide was written by Piotr, a software engineer with hands-on experience building and maintaining web scrapers at scale. He develops and maintains a suite of data extraction tools on the Apify platform, helping businesses automate their data collection workflows.
Need help with your scraping project?
Book a free discovery call and let's scope your project together.
Book a Call